
When we launched Gremlin late last year, we knew the journey ahead would be two-fold. First and foremost, we would need to educate companies, ultimately changing the way they think about operations and shifting the culture to be much more proactive. And then we’d need to build a product which enabled them to do just that. We knew that in traditional organizations, too much engineering time was spent fighting fires and addressing problems after they’ve already impacted customers.
Today, we’re proud to name DTCC, Expedia, Twilio, Walmart and dozens of others as proponents of proactive failure testing and customers of Gremlin. As the CTO of a company in a nascent field, I believe it is my top priority to listen to customers and build products that enable them to be successful in an ever-changing world.
After hearing repeatedly that our customers wanted to be able to run experiments on their containerized infrastructure with the same simple experience as they are able to on traditional hosts, we made some key improvements to the Gremlin product that we are happy to share publicly today.
1) Container Discovery
Containers are yet another step in the direction of ephemerality when we talk about infrastructure. The idea that they can and should be able to come into and out of service makes for increased reliability, but often at the cost of visibility. Add to the mix orchestrators like Kubernetes, and there’s a good chance you may not know exactly where your containers are running at any given moment. That’s why we built Container Discovery: to take the manual process out of identifying your containers and make targeting containers as easy as clicking a button.
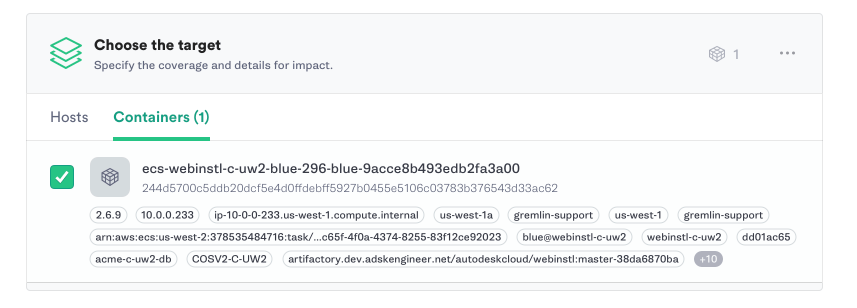
2) Random Attacks
While we are doing all we can to rectify the prevailing stigma that Chaos Engineering must be performed “randomly”, random failures do happen and many companies still value the ability to inject random failure into their systems. With the advent of container discovery users can now easily target a random subset of containers simply by providing a set of tags / labels.
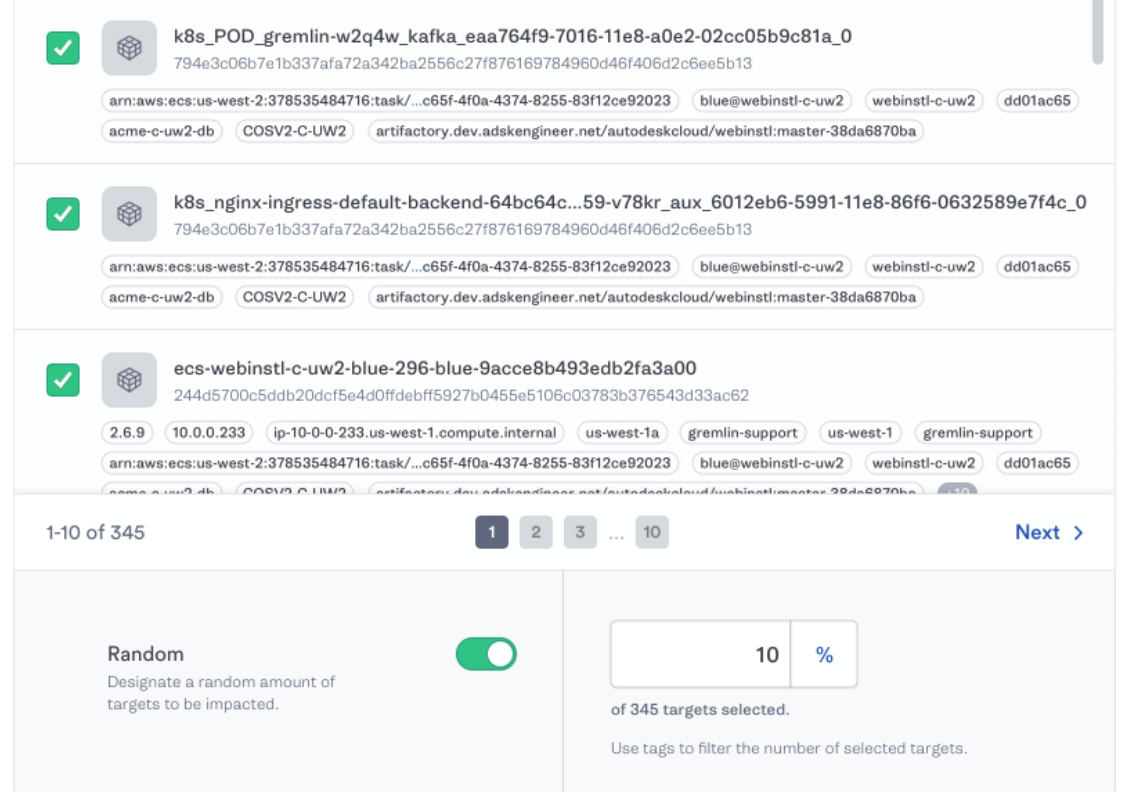
3) Multiple Attacks
When something goes wrong, it’s rarely due to a single point of failure. As a result, we’ve introduced the ability to run multiple failure modes on containerized infrastructure, allowing customers to simulate more complex failure scenarios.
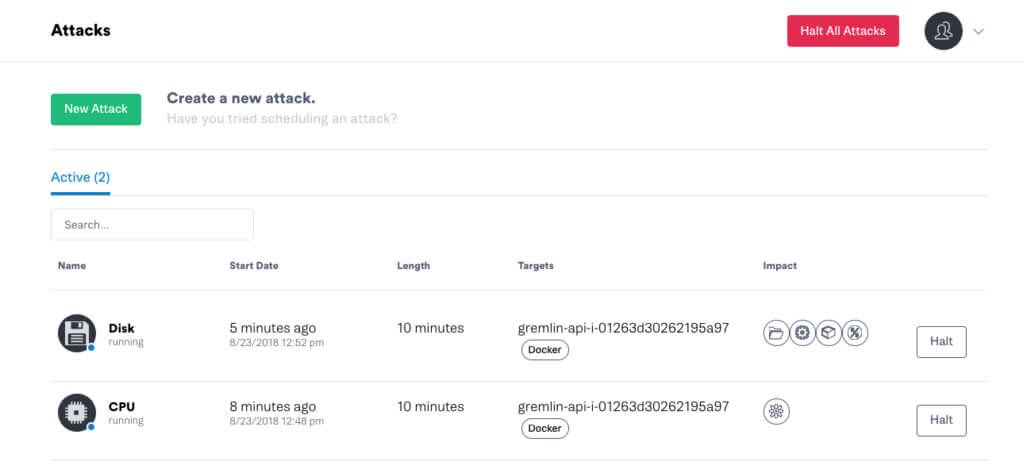
It is now easier than ever before to run Chaos Engineering experiments across your highly dynamic, ephemeral container infrastructure! If you are not currently a Gremlin user, you can always sign up for a free trial or join our community to learn more about Chaos Engineering.
Happy breaking things :)

