
We’re growing up. Nearly a year ago, we officially launched Gremlin’s Failure-as-a-Service platform for running Chaos Engineering experiments across hybrid infrastructure simply, safely, and securely. We started our journey with $7.5Million in Series A funding led by Index Ventures and Amplify Partners, as well as a handful of customers looking to increase their system’s reliability.
Today, we are proud to announce we’ve raised an $18Million Series B funding round led by Redpoint Ventures. That money will be used to hire some of the best engineering talent in the world, building our product to be even more secure and user-friendly, and increasing product velocity to add more value to our users. We’ve added big customers like Twilio, Under Armour, and Walmart Labs that have been crucial in providing feedback and shaping our roadmap.
In that spirit, I am also excited to announce Gremlin’s second major product offering -- Application-Level Fault Injection (ALFI). Now with Gremlin’s Failure-as-a-Service platform, in addition to running chaos experiments on your hybrid infrastructure, ALFI will empower DevOps teams to safely inject failure at the application level for full-stack reliability, including serverless environments.
ALFI is currently in an open beta.
Highlights
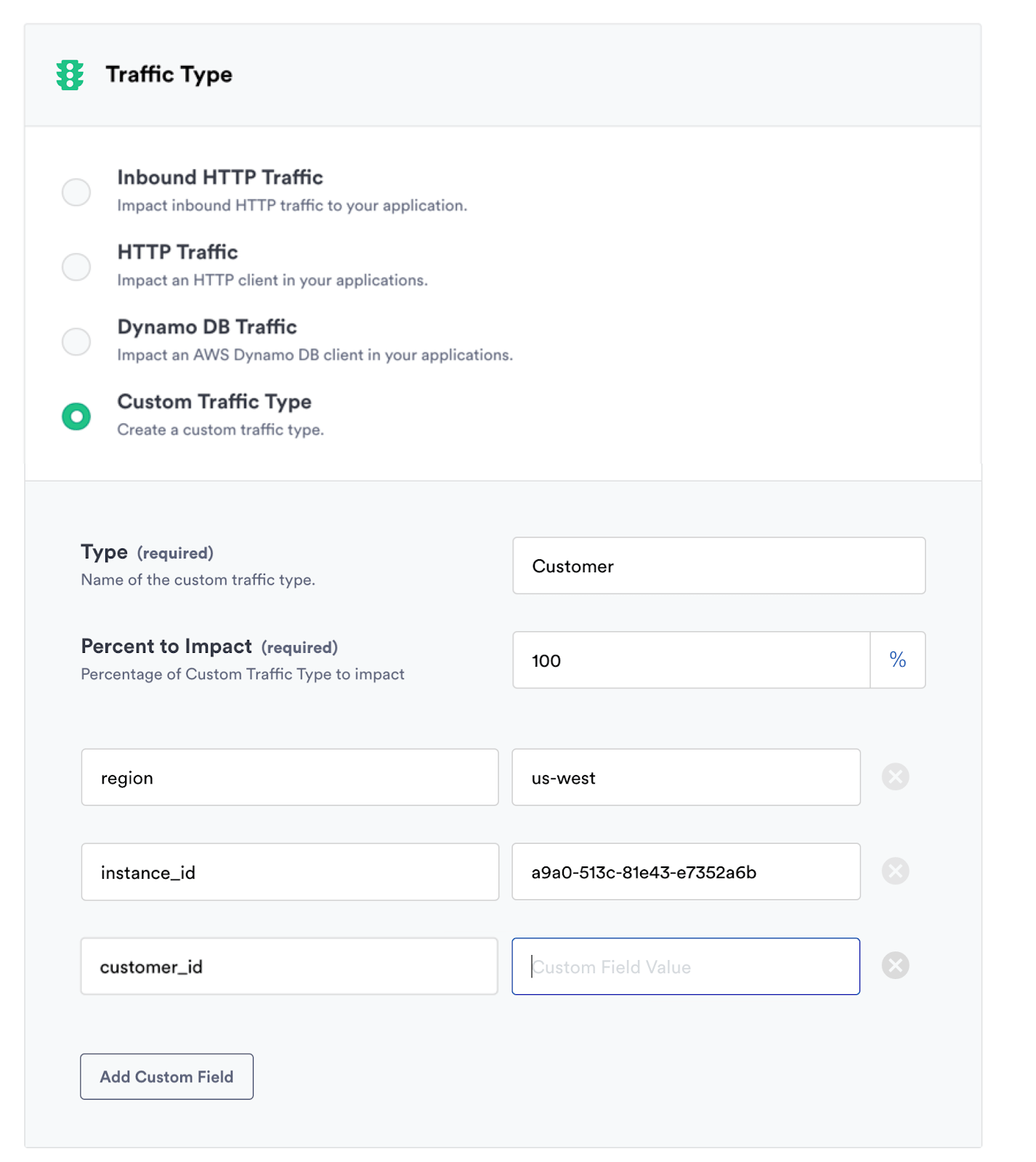
1) Precise fault injection
ALFI allows you to inject failure by matching any attribute you're already using. You can precisely scope attacks to only impact particular customer IDs, locations, device types, etc. after integrating ALFI into your application. This makes it simple to create chaos experiments with a very small blast radius, in order to quickly test hypotheses and gain confidence in your architecture.
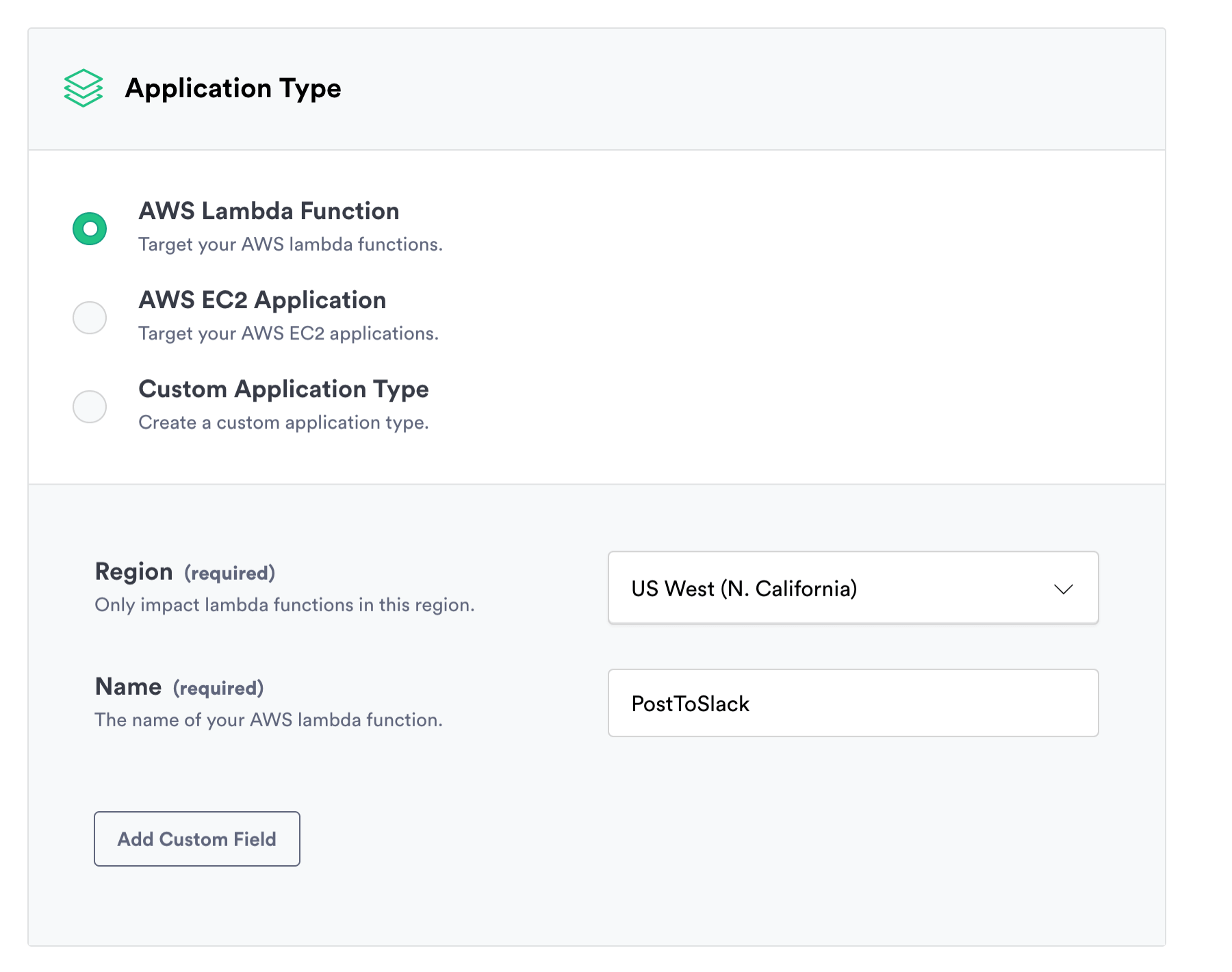
2) Works with your application wherever it’s hosted
Since ALFI is embedded within your application, it will work in any environment you're already using. This includes all serverless platforms like AWS Lambda, Azure Functions, and Google Cloud Functions.
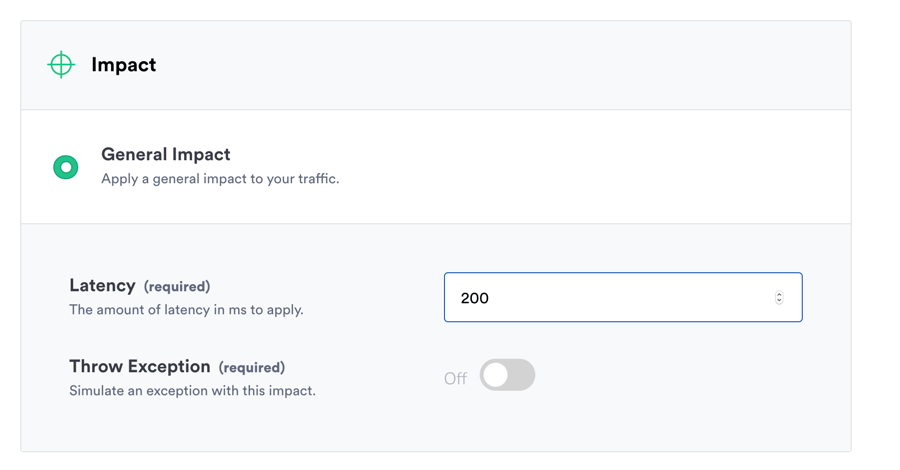
3) High Fidelity to reproduce real-world scenarios
Many incidents in a microservices environment are due to a slowdown or failure somewhere in the constellation of upstream dependencies on which you rely. ALFI simulates delay and/or full-fledged failure of specific services, specific RPC calls, and external dependencies. This lets you confidently reproduce outages, proactively find latent failure modes before they bite you, and prepare for more complicated scenarios where multiple components fail.
Thank you to everyone who has supported and joined the Chaos Engineering community. We are learning from you all every day. Behind our technology is a passionate team from companies like Amazon, Netflix, Salesforce, and Dropbox who have felt pager pain and have been call leaders responsible for triaging and resolving outages. We firmly believe in shifting the operations burden from reactive to proactive. We are committing to building the platform that makes this possible, leading to more productive companies and a more reliable internet for all of us.
-- Kolton

