
Fulfillment pipelines for order management in e-commerce have a lot of intricate moving parts that depend on one another. Sales orders, fulfillment, negotiation, shipment, and receipt are closely interconnected but require different actions while depending on one another closely. You also need messaging around order statuses, conditions, actions, rules, and inventory, just to name a few of the important parts of these complex systems.
Because of the tight dependencies between the various parts of the system, problems such as latency, call failures, and general system hiccups can lead to failures in mission-critical components. When one component fails, the others also fail, usually with catastrophic consequences.
To this end, building a fulfillment center around a simple restful API service architecture may be insufficient. To add resiliency, some architects implement messaging solutions that elegantly pass a workflow through the pipeline, ensuring that every part of a dependency chain can inject its value and move the message to its next destination.
In this article, we'll experiment with such an architecture. We'll use Chaos Engineering to inject faults into a fulfillment center architecture based around message streams to see if it truly is resilient, and to help us determine if this is a reliable solution.
The system today
For our example, we'll use an online retailer that has grown from a small retail order system to a full-fledged fulfillment center. The current system is rich in functionality, with different components for processing orders, collecting shipping details, calculating costs, and many other features. Components call one another to determine what to show the user and how to submit appropriately charged payments to sellers. The system also generates shipping tags and coordinates with carriers to get the best prices and quickest delivery times.
Traditionally, to accomplish this, user requests would have to move through a litany of dependencies:
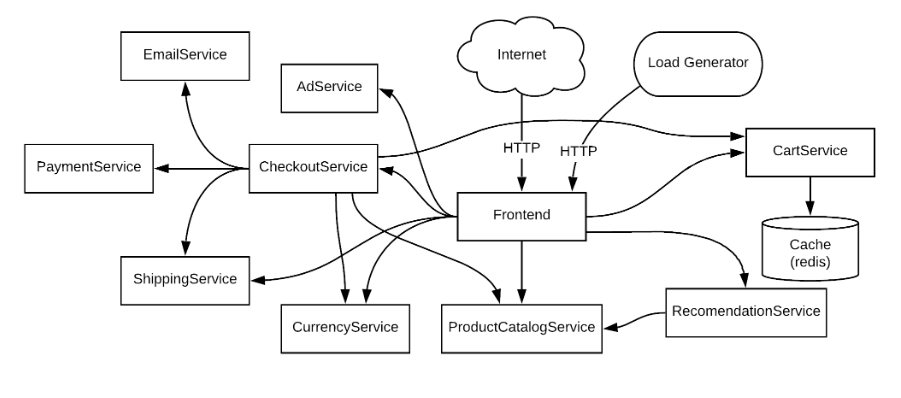
https://github.com/GoogleCloudPlatform/microservices-demo
It's unclear what the system behavior might be at any point, and the high complexity makes it difficult to both maintain stability through various system deployments and ramp up new developers.
Any failures to a complex system such as this risk extra latency and errors to end users. In the online-centric community that we live in today, consumers expect instant gratification and consistent results. Therefore, detraction from this experience impacts not only the system stability and capability, but also incentivizes users to leave for better products.
Even a single failed dependency has the ability to take down this entire site. To prevent this from happening, we need a way to decouple components from each other.
The messaging promise
Messaging solutions like Apache Kafka allow us to decouple multiple components by creating a separate message stream. Components can publish messages to a stream, and other components can subscribe to the stream to consume messages. Unlike the traditional model, publishers don’t need to be aware of specific subscribers. Because of this decoupling, the application can interact with the data in a way that does not result in the service dependencies impacting each other and thus can help prevent a system-wide outage when something unexpected occurs.
Bernd Ruecker of Camunda wrote a great article about the value of consolidating workflows that require extreme resiliency in an effort to combat the complexity of distributed systems within processes like our order fulfillment system.
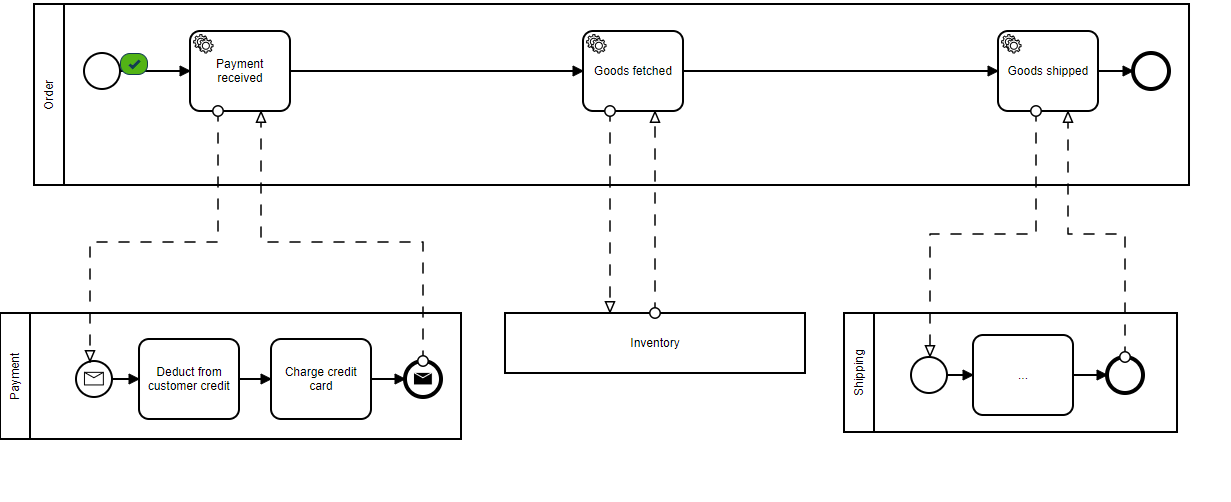
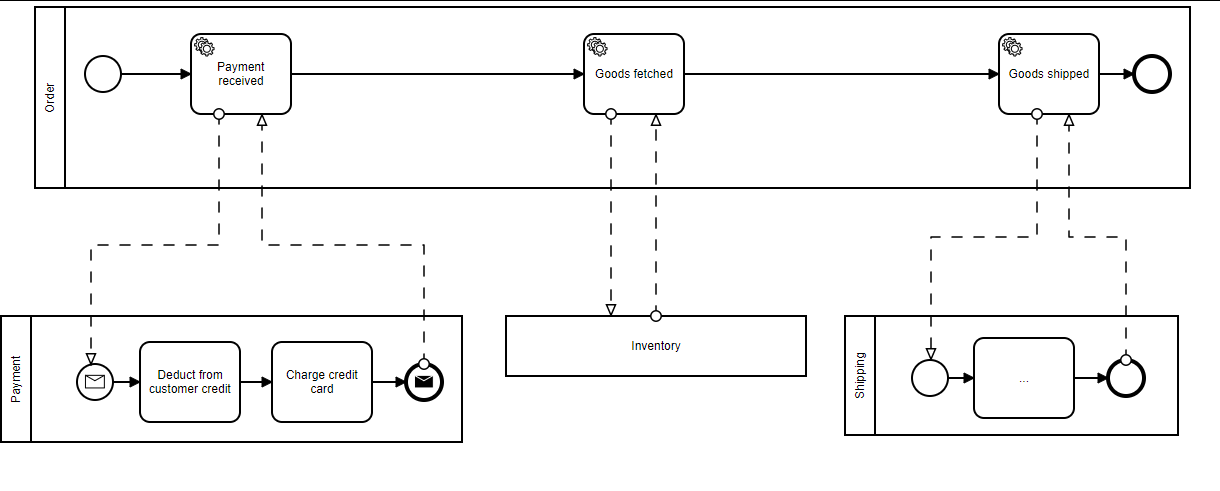
For example, checkout is a critical process that should always be available with low latency, even if a dependent service is down. Below we can see our greatly simplified synchronous pipeline for the CheckoutService step as recommended in the article:
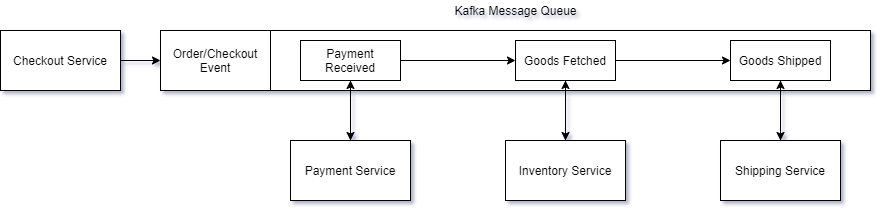
The purpose of this design is to ensure that no service depends on another directly. By using a Kafka message stream, we create a trusted (and guaranteed) method of passing data from one service to the next. In what is referred to as a pub/sub model, components can publish events to the stream, as well as subscribe to events they are interested in. If at some point a service is down, the events are still available on the stream when the service comes back up, at which time the service can complete its portion of the pipeline. No 500’s, no added network latency—just simple data processing.
Validating the promise
The solution is vastly simplified from the current paradigms, but is very different from the service-oriented RESTful endpoints common today. To ensure that the effort is worth the promise of greater reliability, let’s use Chaos Engineering to design and implement some attacks. Chaos Engineering is the science of performing intentional experimentation on a system by injecting precise and measured amounts of harm to observe how the system responds in order to improve the system’s resilience. By triggering these failures in a controlled way, you can find and fix flaws in your systems, giving your team confidence both in your product and in its ability to deal with unforeseen failures.
We'll use Gremlin to set up and run attacks, which is how we’ll inject harm into our systems. Observing how our systems behave during and after these attacks will help us determine how resilient our architecture is and where it falls short before investing the time and energy in changing the entire system.
To test this technology and architecture layout, we’ll build on Bernd Ruecker’s example found here. We have this deployed to our Kubernetes cluster and will be using the Gremlin Kubernetes agent to inject infrastructure and service failures while using our LinkerD service meshes to monitor for app behavior and customer reach-ability. We’ll also use Confluent Control Center to monitor the Kafka message backlogs.
Current system baseline state
Below you can see our current system's baseline state: our service mesh’s monitor of Success Rate (“Total HTTP 200s/total calls”), RPS (“Requests per Second”), and 95th percentile latency (“The slowest calls”). We'll use this baseline to see deviations as they happen in real time during testing. These metrics are from the perspective of the Checkout Service as it is the only service exposed to a customer call.
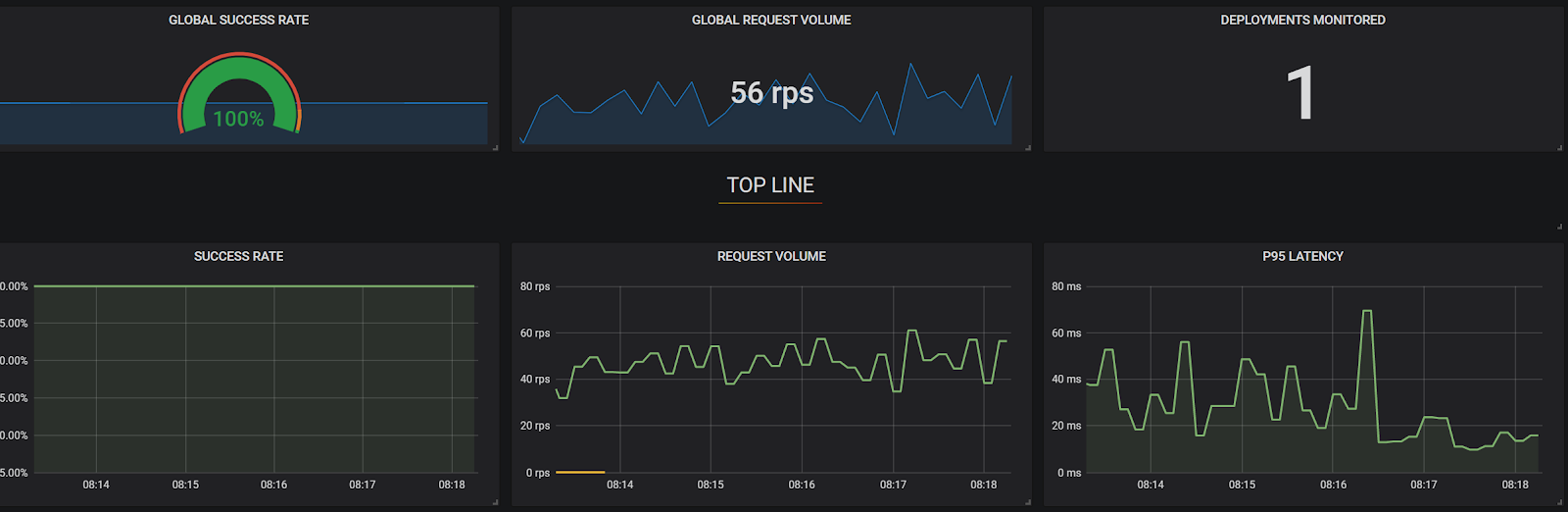
Consistent ebbs and flows as well as 100% success rate is the norm.
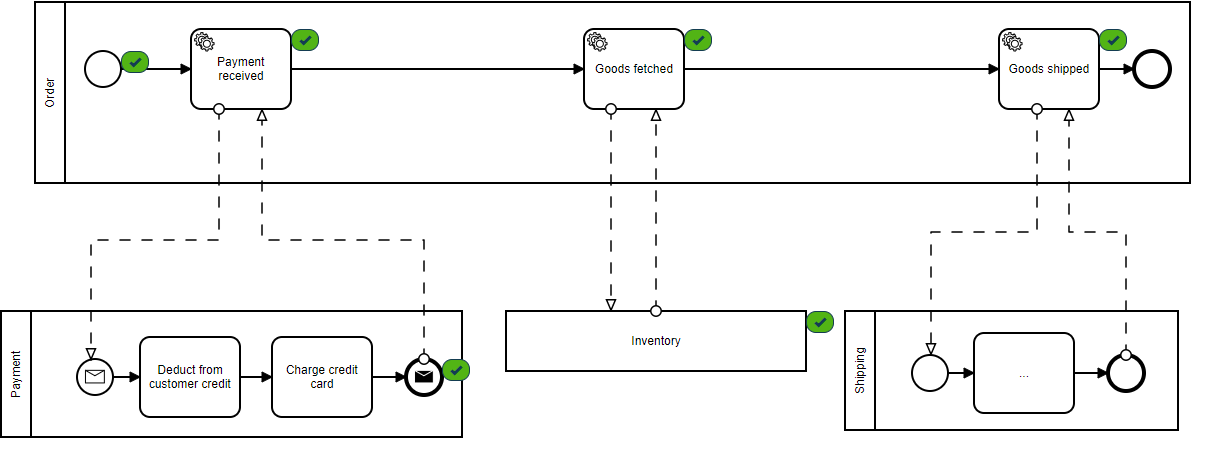
As this is testing a pipeline with no real customer observability, we'll watch the progress of the pipeline through the provided monitor which shows our stages of completion at each step.
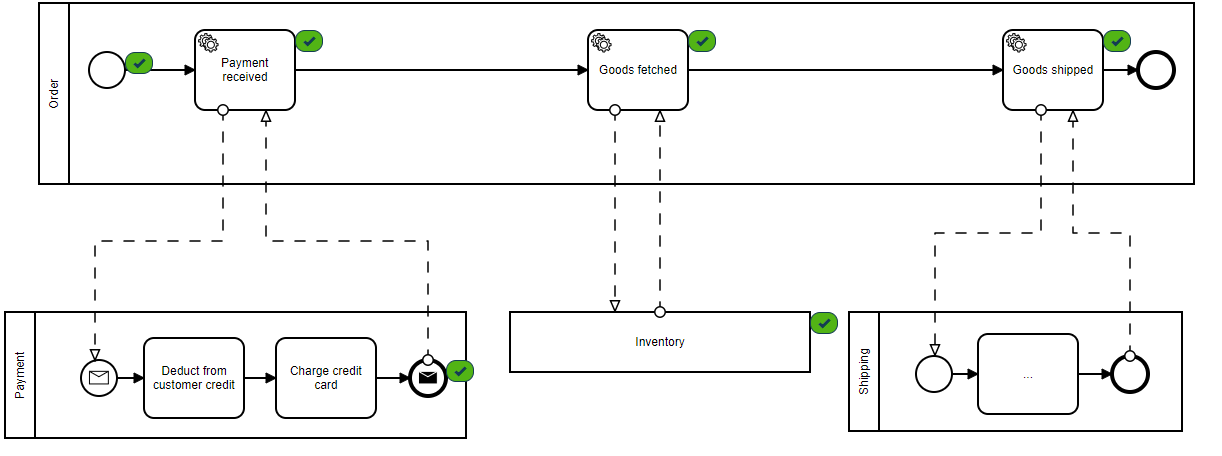
Green check marks indicate completed messages by each consumer.
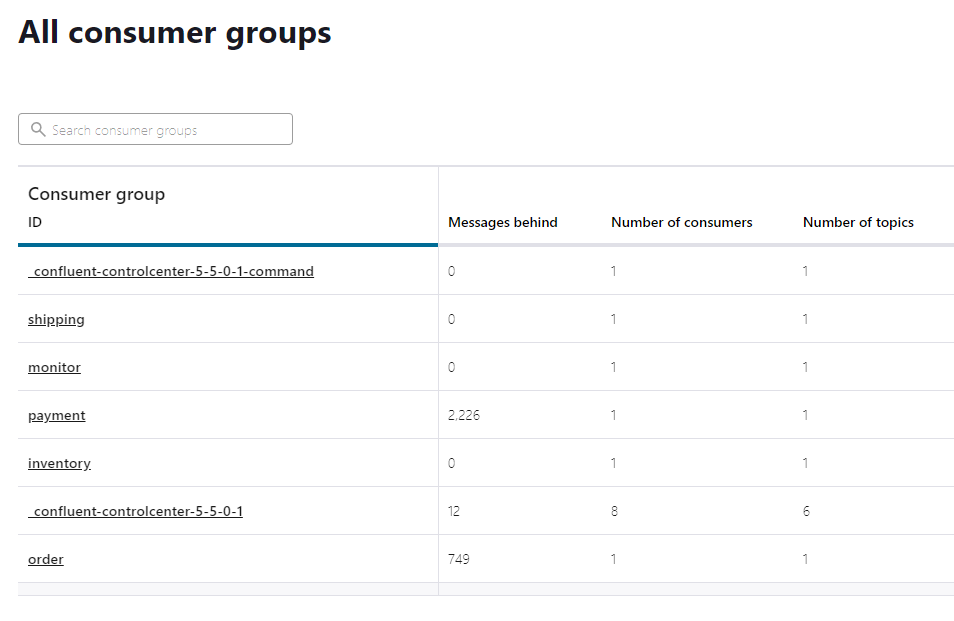
Consumers are the applications that are reading the event stream from Kafka. Here we can see how up-to-date each service is with the event stream.
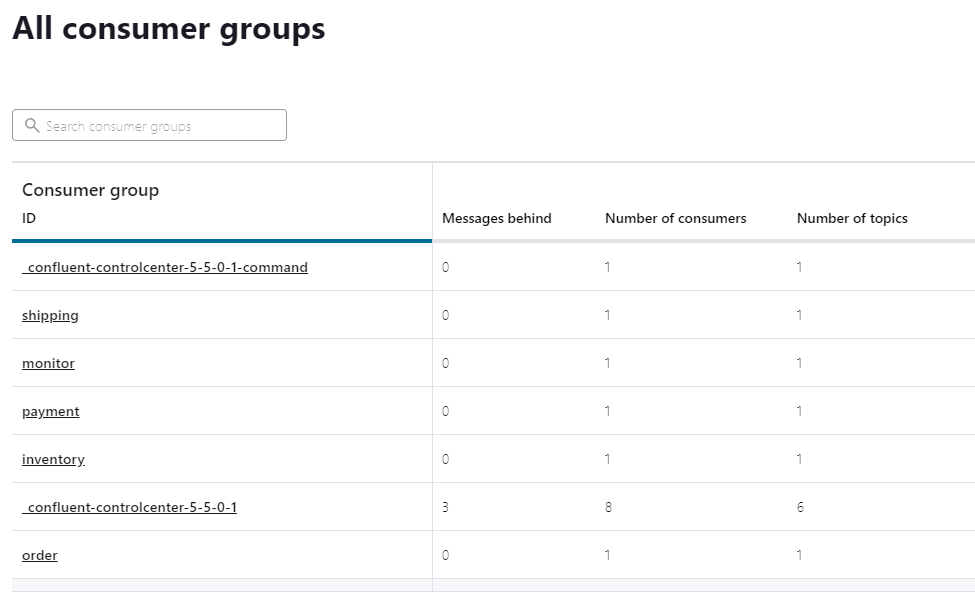
“Messages behind” column shows 0 in each service consumer group, indicating that all messages that have been submitted have been successfully processed.
The chaos experiments
Now let's run our chaos experiments. We'll run three tests that each inject a different possible fault into our system: latency, dropped packets, and loss of the event stream. This will help emulate the soft failures that commonly lead to failures in RESTful applications, as well as test our pipeline when our newest piece of architecture fails completely. A well-designed chaos experiment has several components: a hypothesis stating the question we’re trying to answer, a blast radius and magnitude specifying the scope and intensity of the experiment, a way of measuring system response, and a way to halt and rollback the experiment. We won't go into the detail of these steps in this article, but here is a good resource for more information on designing your chaos experiments. For each of our tests below, we've outlined the hypothesis, the experiment details, and the results.
We’ll use Gremlin, a Chaos Engineering SaaS platform, to run our chaos experiments. You can try these chaos experiments for yourself by creating a Gremlin Free account.
Create your Gremlin Free account
Test 1: Injecting latency between the payment service and the message stream
Hypothesis: Adding latency between the payment service and message stream should cause a backlog in the payment consumers as the impacted service takes longer to complete the calls. However, after a brief catch-up period, the stream should clear and operations should return to normal.
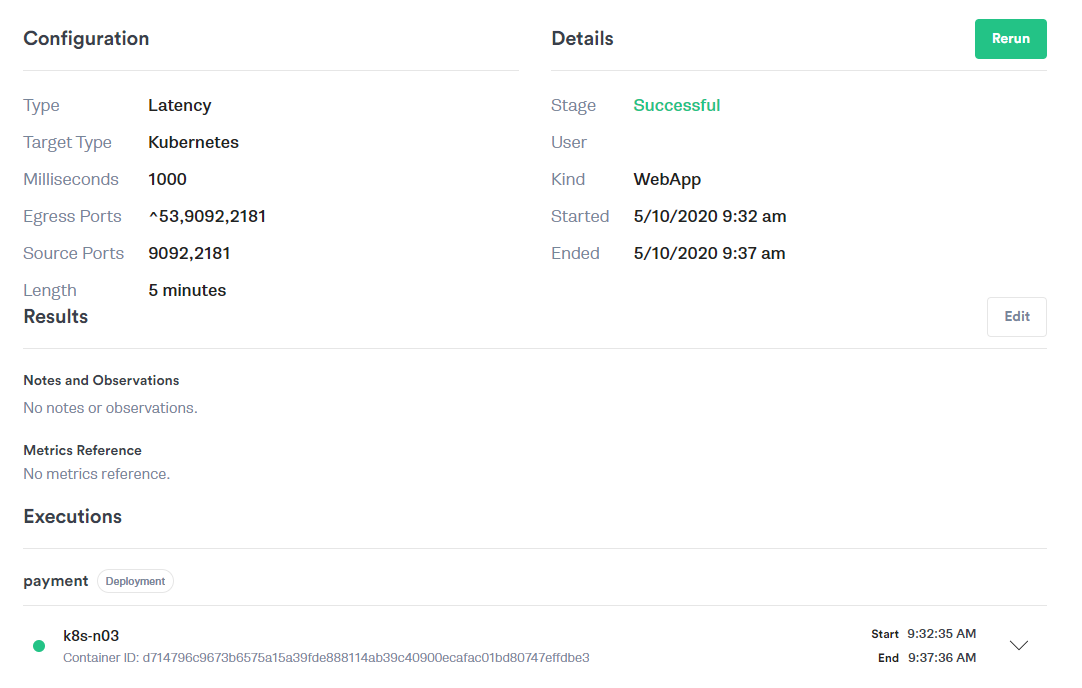
Experiment: Add one second of latency between the Payment Service and the Kafka message stream for five minutes. Here you can see the details of our Gremlin configuration:
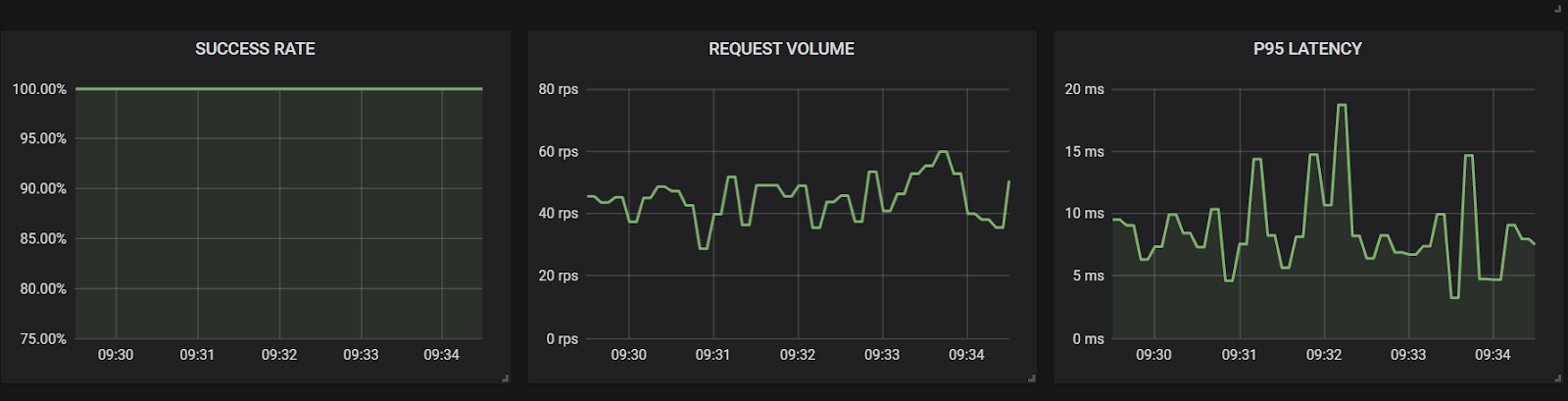
Results: Based on the below results, we can see that the user does not see any increase in latency and calls are not failing to reach the destination. As far as the user is concerned, there is no impact during this test.
Watching the pipeline, however, we can see that the calls are getting stuck on the payment section for a short period:
We can also see that the event pipeline has a growing backlog in the payment service and that other services are processing data as it reaches them without issue. This does settle into ~2,000 message delays on average, meaning the service is able to eventually process these events even with the latency.
Albeit delayed, messages are processed and orders go through eventually. Our test proves that our architecture can successfully handle this latency.
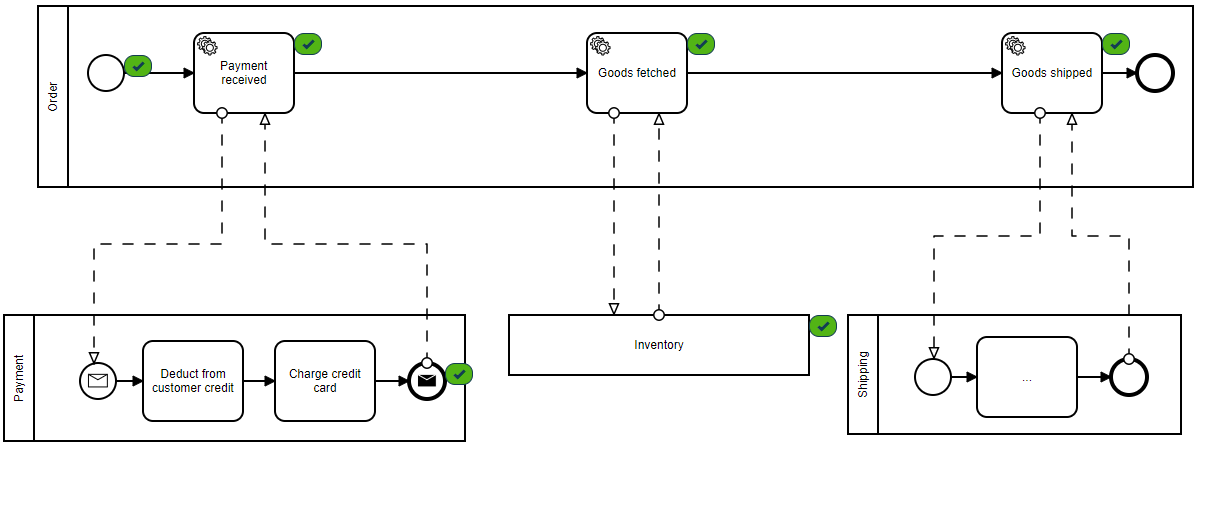
Test 2: Packet loss between a service and the message stream
Hypothesis: Kafka should automatically resend dropped packets sent to the message stream, creating no discernible impact.
Experiment: Inject 20% packet loss between the Inventory Service to the Kafka stream for five minutes using the Gremlin Packet Loss attack. Our Gremlin configuration looks like this:
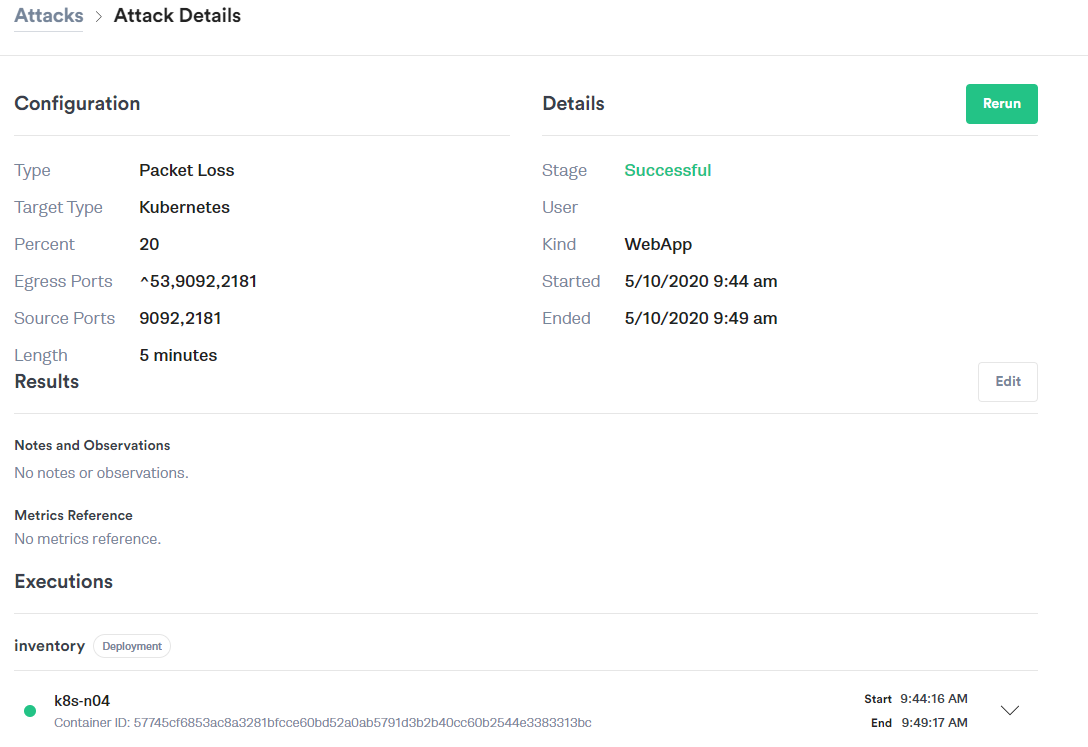
Results: Again we see no impact to the end user. We see a lesser impact on the inventory message backlog than we did on the latency injection, and orders still complete successfully with networking retries handling the loss gracefully.
From the perspective of the customer, we see no relevant latency increases, and no extra failed calls.
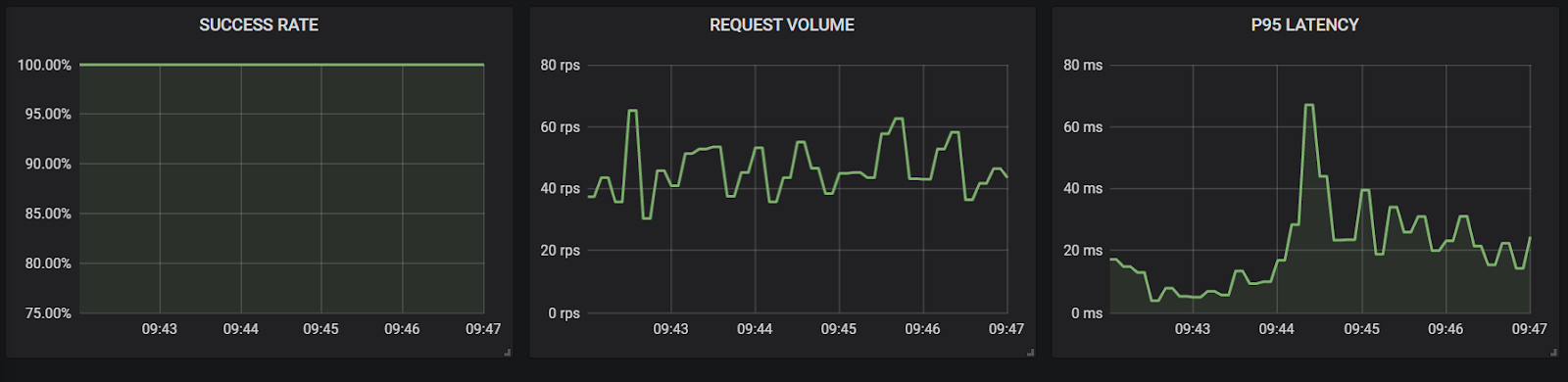
Even from the back-end processing, it appears that all tasks are completed in a timely manner.
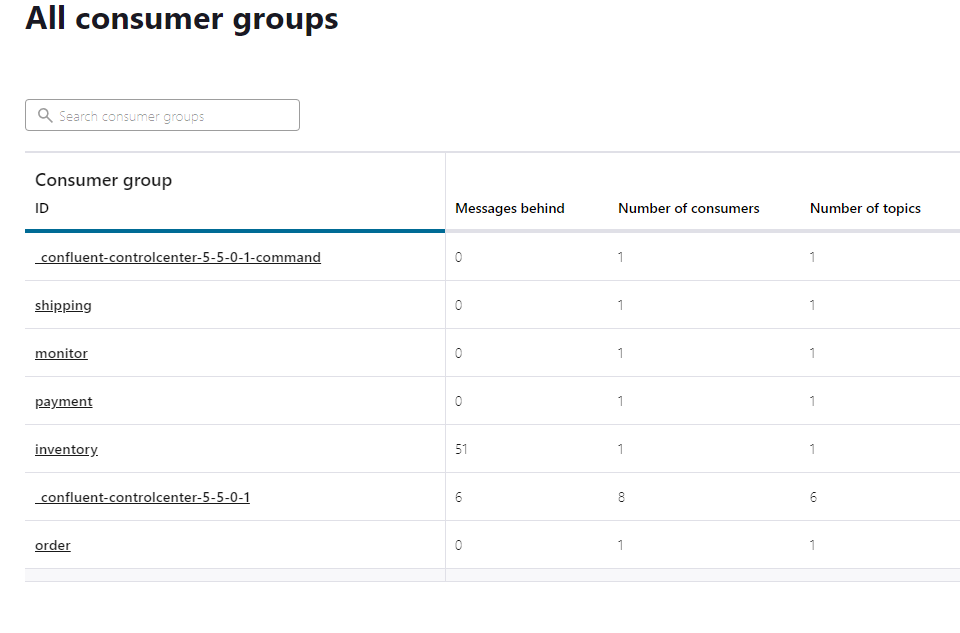
There are some periodic backlogs in messages consumed by the inventory service, however, this is much smaller than the latency tests.
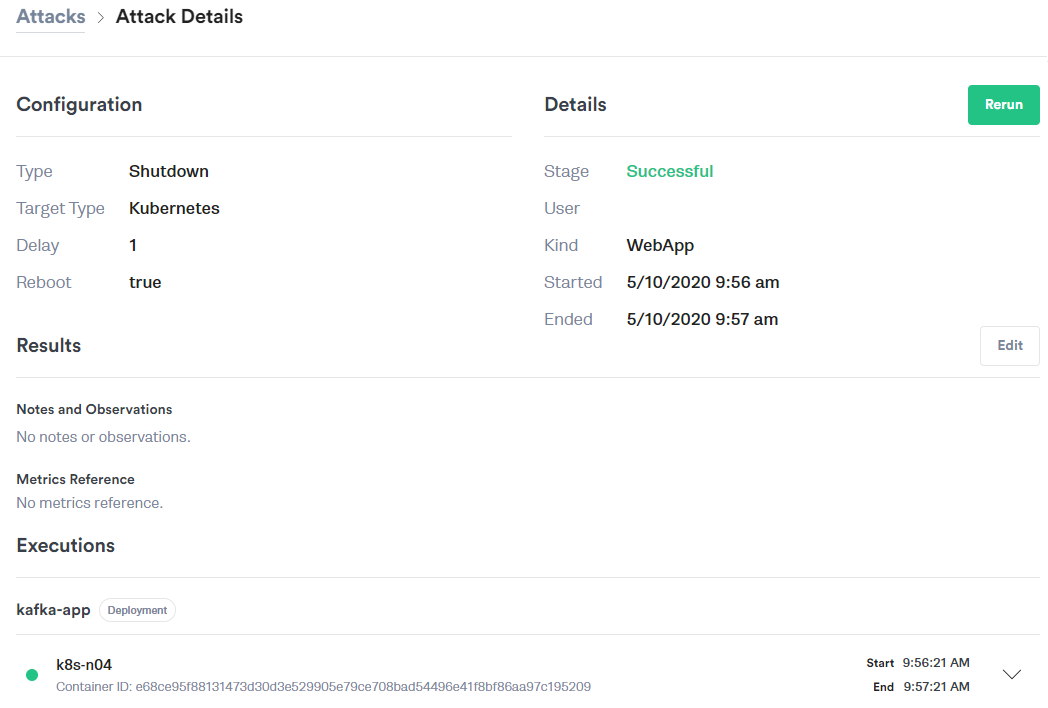
Test 3: Shutdown of the Kafka Message Stream
Hypothesis: Shutting down or rebooting Kafka causes some requests to be lost, resulting in missed purchases.
Experiment: Using the Gremlin Shutdown attack, we'll reboot and then shut down the central Kafka broker dependency while observing the behavior between each step. Again, here is our Gremlin configuration:
Results: Surprisingly, during a restart of the service, we only see a spike in latency (as seen in the first metrics graph below) while the Checkout service cannot inject the event into the system. Eventually it completes as Kafka quickly recovers and the user sees a noticeable delay in processing. Fortunately, there aren't any failures.
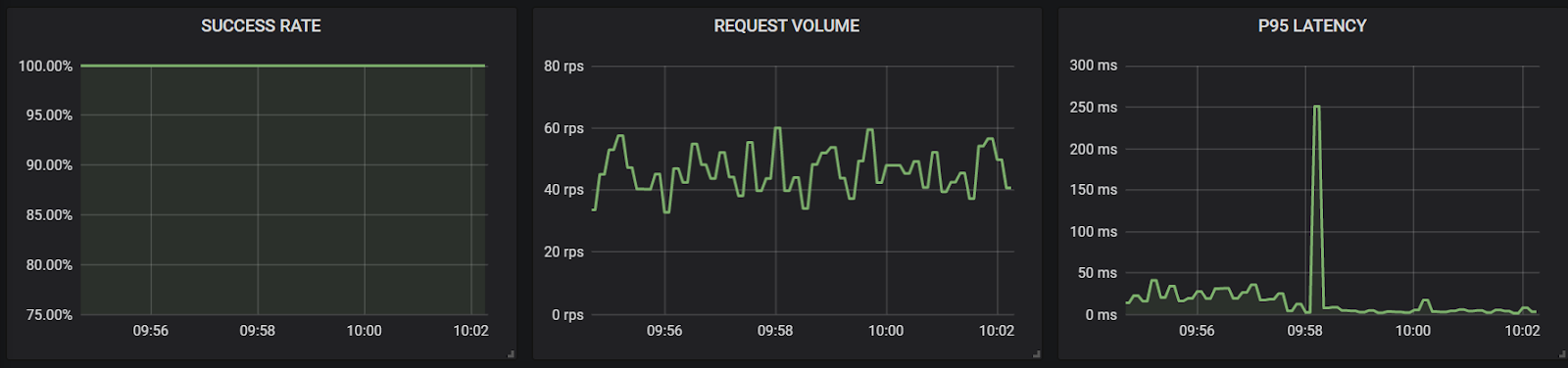
However, when the Kafka broker is instead shut down, it is unavailable for long enough that the calls themselves begin to fail as they eclipse the timeout values of the checkout service. Instead of completing their purchase like normal, users will instead see errors. We can see here the massive increase in latency to 50 seconds as the Checkout service struggles to comply with the inbound requests.
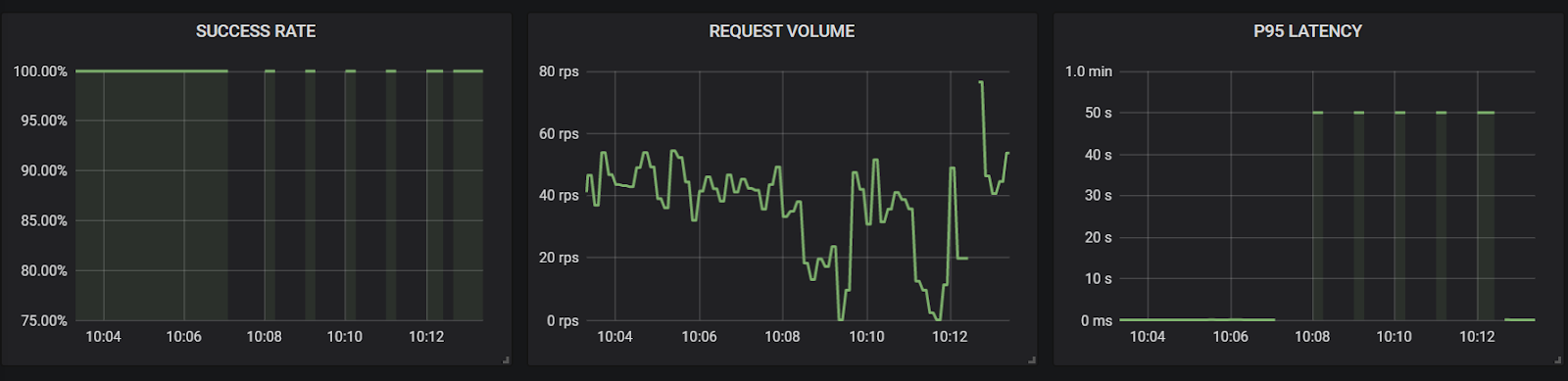
Here is one example request that never reaches the message stream as the customer’s order is lost with the Kafka broker unavailable. This shows us a new single-point-of-failure in this design, and the impact of this dependency failing.
An additional note on this behavior, to recover from the Kafka broker shutdown, the Zookeeper nodes and all consumers must be restarted before the Kafka broker could fully recover and allow traffic to populate its data stores. As a result, any requests that were pending were lost.
Conclusion
The Kafka message stream is a very resilient system, but it certainly isn't without its faults. Through data analytics and consistent testing, we have proven where faults exist (loss of intention due to message stream unavailability) and where this new model has improved the system (packet loss and latency no longer bring down the site).
Now that we are aware of this single-point-of-failure and the necessity for high resiliency in the Kafka system, we can elect a Kafka cluster configuration with better availability, and caching mechanisms on the Checkout service to better store intent until it is processed. This removes the need for Kafka to be always available. We've also validated that the model as designed is a more robust architecture than our previous one, and warrants more investigation into the feasibility of this feature set.
Once the updated model is ready, we can lean on Gremlin and Chaos Engineering to again prove our hypothesis and give us the data we need to be certain that our design adequately meets our business needs.

